交互作用の可視化
心理学(に限らないが)で分散分析を行う場合に、交互作用を可視化することなどを目的として、折れ線のグラフが作られることがありますよね。
主に2要因の場合で、水準数もさほど多くないときに、第1の要因をX軸に、第2の要因は線の種類でかき分けて、Y軸に各群の従属変数の平均値を取る。
こんな感じで。
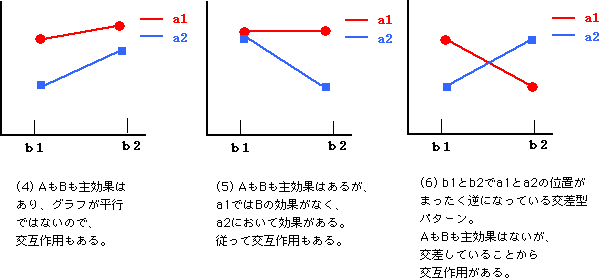
(出典:7.3 交互作用とは?より。)
線の傾きが違えば、交互作用があるってことです。
これ非常によく見かける図ですが、Rでどうやって作図すれば良いか、パッとはわからなかった。
何か良いパッケージがあるのかもしれないけど調べるのもめんどうなので、以下のようにx軸に配置したい要因の各水準にダミーで数字を当ててムリヤリ折れ線グラフとして描いてみた。
作図
たとえば英語の点数(平均)が、

というような結果になっているとする。
男性より女性のほうが成績がよく、かつ理系より文系のほうが成績が良い。
各セルにはサンプルが何十人かいてその平均値が上記の通りとなっており、その平均値が男女間、文系理系間で有意に異なるのかどうかを、2要因の分散分析によって検定する。
で、その前に、まず平均値を表すグラフを描いておきたいと思ったとする。
以下のように書くと、組み込みの関数でそれっぽいグラフが描けました。
x軸をいったん消しといて、axisで上書きするところがポイント。(あまり調べてないので、もっと良いやり方があるのかも知れない。)
Male <- c(81.3, 85.5) Female <- c(83.7, 91.8) # 男性のほうのグラフを描く plot(x=c(1,2), # ダミーで数字を入れている y=Male, type="b", # 点と線をプロット lty=1, # 線を実線に lwd=1.5, # 線の太さ1.5倍 xlim=c(0.7, 2.3), ylim=c(80, 95), xlab="文理", ylab="点数", xaxt="n", # x軸を消すという意味 pch=21, # 白丸 cex=1.5 # 丸の大きさ1.5倍 ) axis(side=1, # x軸を描くという意味 at=1:2, # 目盛り labels=c("理系", "文系") # 目盛ラベル ) # 女性のほうのグラフを重ねる par(new=TRUE) # 上から重ねるときのパラメータ設定 plot(x=c(1,2), y=Female, type="b", lty=2, # 線を破線に lwd=1.5, xlim=c(0.7, 2.3), ylim=c(80, 95), xlab="", # x軸のタイトルなし ylab="", # y軸のタイトルもなし axes=FALSE, # 軸なしという意味 pch=21, cex=1.5 # 丸の大きさ1.5倍 ) legend("bottomright", # 凡例の位置 legend=c("男性", "女性"), # 凡例の文字 lty=c(1, 2), # 凡例の線の種類 lwd=c(1.5, 1.5) # 太さ )

凡例が、この例だと線の描き分けだけ表現すればいいので楽だけど、たとえば黒丸と白丸を使い分けたりして、丸の種類についての凡例も載せなければならなくなったりすると、割とめんどくさい。
何がめんどくさいって、凡例の位置を座標で指定してりして微妙に調整するのがダルい。たいてい、思った通りのポジションに表れてくれないし。
凡例が1種類だけでいいなら、この例のように、「右下」みたいな指定をしておけば、ずれたりすることもなく安心。
話がそれますが、凡例のことを英語でlegendと言い、legendには言うまでもなく「伝説」という意味もあります。なんで凡例と伝説が同じ単語なのかについて、「手本」みたいな意味があるのかと思ってたのですが、語源辞典によればラテン語で「読むべきもの」という意味の言葉からきているようです。
まんま使える関数が存在した(2016.1.8追記)
このエントリアップ後、Twitterで教えてもらったのですが、interaction.plot()という、そのまんま上記目的のための組み込みの*1関数があったようです。
以下のように使います。
# テスト用サンプルデータを乱数で生成 set.seed(1) Score <- c( rnorm(100, 81.3), # 男性・理系 rnorm(100, 85.5), # 男性・文系 rnorm(100, 83.7), # 女性・理系 rnorm(100, 91.8) # 女性・文系 ) # 因子をつくっておく Sex <- c( rep("Male", 200), rep("Female", 200) ) Class <- c( rep("Rikei", 100), rep("Bunkei", 100), rep("Rikei", 100), rep("Bunkei", 100) ) # データフレームにまとめる # 理系→文系の順に並べたいので水準ベクトルの順番を自分で指定している df <- data.frame( ID=1:400, Sex, Class=factor(as.factor(Class), levels=c("Rikei", "Bunkei")), Score) # 作図する quartz(width=8, height=6) # 作図デバイスのサイズ指定(Macの場合) par(mai=c(1, 1, 0.7, 0.7)) # 余白の指定 interaction.plot( x.factor=df$Class, # x軸の変数 trace.factor=df$Sex, # 線で描き分ける変数 response=df$Score, # y軸の変数 fun=mean, # 平均値を図示するならmeanを指定 type="b", # 点と線で表すグラフを指定 legend=TRUE, # 凡例あり ylim=c(80, 94), # y軸の範囲指定 xlab = "Class", # x軸タイトル ylab = "mean of Score", # y軸タイトル trace.label = "Sex", # 線で描き分ける変数タイトル(凡例に出る) pch=c(19, 21), # 丸の記号の種類 cex.lab=1.2 # 軸タイトルの文字サイズ )
こんな図が出来ます。

めちゃめちゃ綺麗やん!!!!!!!
4つの平均値しか情報がないグラフなので、文字を大きくしてグラフ自体はもっと小さくして簡単な感じにした方がいいけど。
ついでに、グラフが交差するパターンも描いておいた。乱数のところを、
set.seed(1) Score <- c( rnorm(100, 82.9), # 男性・理系 rnorm(100, 87.5), # 男性・文系 rnorm(100, 81.1), # 女性・理系 rnorm(100, 91.8) # 女性・文系 )
に変更。

*1:標準パッケージの、と言うほうが正確なのかな?