先日から英日Transformerの学習結果の報告を何度か書いてますが(エントリ1・エントリ2・エントリ3)、AWSでA100というGPUが8枚使える最高スペックのインスタンスが空いたので*1、コーパスとモデルを少し大きくして、Googleの有名な“Attention is all you need”論文のベースモデルに近い規模にしてみました。
具体的にいうと、All You Need論文では英語-ドイツ語の翻訳に関しては、
- 450万ペアの対訳コーパス
- 37000トークンのボキャブラリ辞書(byte-pair encoding)
- Transformerブロックはエンコ側・デコ側ともに6層
- 埋め込みは512次元
- マルチヘッドアテンションのヘッド数は8
- フォードフォワード部分の隠れ層は2048次元
- 10万ステップ学習(12時間)
というスペックになっています。ステップは、サンプルサイズ÷バッチサイズという理解であってるかな?
私が今回構築したのは、英語-日本語の翻訳モデルで、
- 580万ペアの対訳コーパス
- 30000トークンのボキャブラリ辞書(byte-pair encoding)
- Transformerブロックはエンコ側・デコ側ともに6層
- 埋め込みは512次元
- マルチヘッドアテンションのヘッド数は8
- フォードフォワード部分の隠れ層は2048次元
- 10万ステップ学習(25時間)したが勾配累積してるのでパラメータの更新回数はその4分の1になる
という規模です。前回からの変化としては、コーパスの規模が170万から580万に増えたのと、フィードフォワードの次元が512だったのを2048にしています。ちなみに使っているコーパスは、以下のような無料のものをクリーニングして合体して使っています。
- TED字幕(元データは15万8535件/うち15万5723件使用)*2
- 青空文庫等の小説(元データは11万8143件/クリーニングとデータ拡張処理を経て11万1485件使用)*3
- 京都Wiki(元データは44万3849件/うち13万4199件使用)*4
- 映画字幕(元は280万1388件/うち125万5207件使用)*5
- 田中コーパス(元データは14万7918件/うち14万4683件使用)*6
- 法令対訳コーパス(元データは26万2449件/うち17万6054件使用)*7
- JparaCrawl(元データは2574万0835件/うち128万4193件使用)*8
- Wikimatrix(元データは85万1706件/うち58万0375件使用)*9
- Coursera(元データは5万3166件/うち5万2614件使用)*10
- OSSマニュアル(元データは40万3366件/うち26万2067件使用)*11
- ASPEC(元データは300万8500件/うち165万9318件使用)*12
元データの件数は、英語か日本語のどちらかが欠けているデータを除いてカウントしているので、公式の表記より少ない場合があります。これらのコーパスを全部合わせると3398万9855件あるのですが、データを絞って使っています。
まず、全体として英語文10〜500文字、日本語文10〜250文字のものに限ってます。本当は長い文も学習させたいのですが、バッチ内で最長のシーケンスに合わせてパディングされる影響もあって、長い文が少しでも混じってるとメモリを大きく圧迫するので、我慢しました。
またコーパスによっては、日本文に英数字をたくさん含むもの、日本文が句点で終わってないもの、英文が大文字で始まってないもの、日本文と英文の文字数の比率が極端なものなどを除きました。句点で終わってないとかは、それ自体は大した問題ではないのですが、「品質の低い対訳文例」である可能性が少し高いので除いているという感じです。
もともとデータ量が多いコーパスについては、日本語が50文字未満のものをバッサリ削ったりもしてます。どちらかといえば長めの学習データが不足しがちだからです。
句読点を補ったり、日本語が分かち書きされていたのでスペースを削って詰める操作をしたコーパスもあります。
前回、前々回と翻訳結果を比較してみます。コーパスの規模を130万ペア、170万ペア、580万ペアと増やしてきたので、1.3M、1.7M、5.8Mと表記してます。個人的に一番よかったものに★印を付けています。
Your time is limited, so don’t waste it living someone else’s life. (Steve Jobs)
【1.3M】時間は限られているので、他人の人生を浪費しないでください。
【1.7M】時間が限られているので、他人の人生を無駄にしないでください(スティーブ・ジョブズ)。
【5.8M】時間は限られているので、他の人の人生を生きることは無駄にしないでください。★
(拙訳:君たちの時間は限られている。他人の人生を生きるようなことをしてそれを無駄にするな。/スティーブ・ジョブズ)
I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character. (Martin Luther King Jr)
【1.3M】私は4人の小さな子供たちが、いつか、自分の肌の色ではなく、その性格の特徴によって判断されない国家に住む夢を持っています。
【1.7M】わたしには、ある日、わたしの4人の小さな子供が、肌の色ではなく、その性格の色によって判断されるであろう国に住んでいるという夢があります(マーティン・ルーサー・キングジュニア)★
【5.8M】ある日、私の4人の子供たちが、自分の肌の色ではなく、その性格の含みで判断される国に住んでいくという夢があります(マルティン・ルーサー・キング・ジュニア)。
(拙訳:私には夢がある。私の4人の子供たちがいつの日か、肌の色ではなく彼らの人格によって判断される国に暮らせるようになるという夢が。/キング牧師)
You are fake news! (Donald Trump)
【1.3M】偽のニュースです!★
【1.7M】ばかばかしいニュースだ!(ドナルド・トランプ)。
【5.8M】偽りのニュースです!(ドナルド・トランプ)
(拙訳:フェイクニュース屋め!/トランプ大統領)
You may say I'm a dreamer. But I'm not the only one. I hope someday you'll join us. And the world will be as one. (John Lennon)
【1.3M】夢想家だって言うかもしれないけど、私だけじゃない。いつか、ぼくらと合流してくれるといいんだけど。そして世界は、ひとつのものになる。
【1.7M】夢想家だと言うかもしれません。でも、私はただ一人ではありません。いつかあなたたちが仲間になるといいですね。世界は1つになるでしょう。(ジョン・レノン)
【5.8M】夢想家だと言ってもいいけど、わたしだけじゃない。いつかあなたも参加してくれるといいんだけど。そして世界は一つになるよ(ジョン・レノン)。★
(拙訳:夢想家だと君は言うかもしれないけれど、僕は一人じゃない。いつか君も一緒になれれば。そして世界は一つになる。/ジョン・レノン)
The madman is not the man who has lost his reason. The madman is the man who has lost everything except his reason. (G. K. Chesterton)
【1.3M】狂人は理性を失った人間ではない。狂人は、理性以外はすべてを失った男だ。
【1.7M】狂人は理性を失った人間ではない。狂人は理性以外のすべてを失った男である(G.K.チェスタトン)。
【5.8M】狂人は、その理性を失った人ではない。狂人は、その理性を除いて、すべてを失った人だ。(G.K.チェスタトン)★
(安西徹雄訳:狂人とは理性を失った人のことではない。狂人とは、理性以外のあらゆる物を失った人のことである。/チェスタトン)
The safest general characterization of the European philosophical tradition is that it consists of a series of footnotes to Plato. (A. N. Whitehead)
【1.3M】ヨーロッパ哲学伝統の最も安全な一般的な特徴は、それがプラトンへの一連の脚注から構成されていることです。
【1.7M】ヨーロッパの哲学的伝統の最も安全な一般的な特徴は、プラトンへの一連の脚注から成り立っていることである(A.N.ホワイトヘッド)。★
【5.8M】ヨーロッパ哲学の伝統の中で最も安全な一般の特徴は、プラトンへの一連の脚注からなるということである。
(拙訳:ヨーロッパ哲学の伝統について間違いなく言えるのは、その全てが、プラトン哲学へのひと続きの注釈に過ぎないということである。/ホワイトヘッド)
Violence sometimes may have cleared away obstructions quickly, but it never has proved itself creative. (Albert Einstein)
【1.3M】暴力は時々すぐに妨害を片付けるかもしれませんが、それは創造的に証明されたことはありません。
【1.7M】暴力沙汰はすぐに閉ざされたのかもしれないが、しかし、創造的自立は証明されていない(アインシュタイン)
【5.8M】暴力はときどき障害をなくしてしまったかもしれないけれど、創造的だと証明されることはなかった。★
(拙訳:暴力が、問題を手っ取り早く片付けるのに役立つことはある。しかし、暴力それ自身が創造的であったことは一度もない。/アインシュタイン)
正直、そんなによくなったわけではないですねw
今回追加したコーパスのうち、OSSマニュアル(オープンソース・ソフトウェアの説明書の対訳データ)とASPEC(学術論文のアブストラクトの対訳データ)は、内容が専門的なので、言葉のチョイスがそれに引っ張られてしまったかもしれません。
ただ前回も言いましたが、当初はキング牧師の引用文中のbutがうまく反映されず、「肌の色ではなく人格によって判断される」というふうに訳すことが安定的にはできてなかったのですが、今回はbutの解釈自体は総じて的確でした。↑の比較では前回(1.7M)のが一番良いのですが、これはたまたま最終エポックのモデルでうまく訳せていただけという感じだったのですが、今回は下記のように各エポックごとのモデルの結果を並べて見ても、butの解釈(○○ではなく××)自体は安定しています。
contentの訳が安定してなかったり、「one day」を1.3Mの時は「いつか」と訳せてたのに「ある日」とかになってるのは残念ですが……。
一番よかったのはエポック27のやつですかね。
Epoch01: 私は、私の子供達が、その子供達が、その1週間前に、その子供たちの色を、その色に、その色に、その色が、その色(英語版)のスタイルに、その色が、その色に、その色が*13
Epoch02: 私は私の4つの小さな子供が、彼らの皮膚の色によって判断されない国家に住んでいる夢を持っていますが、彼らのキャラクターのコンテンツ(ミートリン・ルーズ・キング・ジョル)によって。
Epoch03: 私は私の4つの小さな子供たちが1日1日に、彼らの肌の色で判断されない国家に住んでいる夢を持っていますが、彼らのキャラクターのコンテンツによって。(マテイン・ルター・キング・Jr)。
Epoch04: 私は私の4人の子供たちが1日1日に、彼らの肌の色によって判断されない国家に住んでいる夢を持っていますが、彼らのキャラクターのコンテンツ。(マティニンルーサーキングJr)。
Epoch05: 私は私の4人の小さな子供たちが1日1日に、彼らの肌の色によって判断されない国家に住んでいる夢を持っていますが、彼らの性格のコンテンツ。(マティインルーサーキングJr)。
Epoch06: 私は私の4人の子供たちが1日1日に国民に住み、彼らは彼らの肌の色によって判断されないが、彼らの性格のコンテンツによって。(マリン・ルター・キング・ジュニア)私は夢を持っています。
Epoch07: 私は私の4人の小さな子供たちが1日、彼らの皮膚の色ではなく、彼らの性格のコンテンツによって判断される国に住んでいる夢を持っています。(マリンルーサーキングJr)。
Epoch08: 私は私の4人の小さな子供たちが1日、彼らの肌の色によって判断されないが、彼らの性格の内容によって、国民に住んでいる夢を持っています。(マリンルーサーキングJr)。
Epoch09: 私は私の4人の子供たちが1日、彼らの肌の色によって判断されないが、彼らの性格の内容によって決定される国に住んでいる夢を持っています。(マリン・ルーサー・キングJr)。
Epoch10: 私は私の4人の子供たちが1日、彼らの肌の色によって判断されないが、彼らの性格の内容によって、彼らが国に住んでいることを夢見ています。(マータンルーサーキングJr)。
Epoch11: 私は私の4人の子供たちが1日、彼らの肌の色によって判断されるのではなく、彼らの性格の内容によって決定される国に住んでいる夢を持っています。(マータンルーサーキングJr)。
Epoch12: 私は私の4人の子供たちが1日、彼らの肌の色ではなく、彼らの性格の内容によって判断される国に住んでいるという夢を持っています。(マルティンルーサーキングJr)
Epoch13: 私は私の4人の小さな子供たちが1日、彼らの肌の色ではなく、彼らの性格の内容によって判断される国に住んでいるという夢を持っています。(マルティンルーサー王Jr)
Epoch14: 私は私の4人の子供たちが、ある日、彼らの肌の色ではなく、その性格の内容によって判断される国に住んでいる夢を持っています。(マルティンルーサー・キングJr)
Epoch15: 私は私の4人の子供たちが、ある日、彼らの肌の色ではなく、その性格のコンテンツによって判断される国に住んでいるという夢を持っています。(マルティンルーサーキングJr)
Epoch16: 私の4人の子供たちが、ある日、その人の肌の色ではなく、その人の性格の形によって、その人の肌の色によって判断されるような国に住む夢があるのです。
Epoch17: 私はある日、私の4人の子供たちが、その人の肌の色ではなく、その人の性格の含みによって、その国の生活をするという夢を持っています。
Epoch18: 私は、私の4人の小さな子供たちが、ある日、彼らの肌の色ではなく、その性格のコンテンツによって判断される国に住んでいる夢を持っています。(マルティン・ルーサー・キングJr)
Epoch19: 私は、私の4人の子供たちが、ある日、彼らの肌の色ではなく、その性格のコンテンツによって、彼らが判断される国に住んでいるという夢を持っています。
Epoch20: 私は、私の4人の小さな子供が、ある日、彼らの肌の色ではなく、その性格の内容によって判断される国に住むことを夢見ています(マルティン・ルーサー・キング・ジュニア)。
Epoch21: 私は、私の4人の小さな子供が、ある日、彼らの肌の色ではなく、その性格の内容によって判断される国に住んでいるという夢を持っています。(マルティン・ルーサー・キングJr)
Epoch22: 私は私の4人の子供たちが、ある日、彼らの肌の色ではなく、その性格の含みによって、彼らが判断される国に住んでいるという夢を持っています。(マルティン・ルーサー・キングJr)
Epoch23: 私は私の4人の子供たちが、ある日、彼らの肌の色ではなく、その性格のコンテンツによって判断される国に住むことを夢見ています(マルティン・ルーサー・キングJr)。
Epoch24: 私は私の4人の子供たちが一日住んでいて、その国の色によって判断されるのではなく、その性格のコンテンツによって判断されるという夢を持っています。
Epoch25: 私は私の4人の子供たちが、ある日、彼らの肌の色ではなく、その性格のコンテンツによって判断される国に住むことを夢見ています(マーティン・ルーサー・キングJr)。
Epoch26: 私は私の4人の子供たちが一日住んでしまう夢を持っています。彼らは彼らの肌の色ではなく、その性格の内容によって判断されるでしょう。
Epoch27: 私は私の4人の子供たちが、ある日、彼らの肌の色ではなく、その性格の内容によって判断される国に住むことを夢見ています(マーティン・ルーサー・キングJr)。★
Epoch28: ある日、私の4人の子供たちが、自分の肌の色ではなく、その性格の含みで判断される国に住んでいくという夢があります。
Epoch29: ある日、私の4人の子供たちが、自分の肌の色ではなく、その性格の含みで判断される国に住んでいくという夢があります。
Epoch30: ある日、私の4人の子供たちが、自分の肌の色ではなく、その性格の含みで判断される国に住んでいくという夢があります(マルティン・ルーサー・キング・ジュニア)。
「性格のコンテンツ」という訳になっているのは、今回追加したコーパスの癖のような気がします。ソフトウェアのマニュアルと学術論文のコーパスを追加したのですが、英語をカタカナで表現してる部分が多くて、その影響が出たのかなと。
以下は学習曲線で、一応検証ロスは微妙に下がり続けているのですが、上記の各エポックの翻訳結果の変化を見るかぎり、後半はあまり頑張っても意味ない気はしますね。
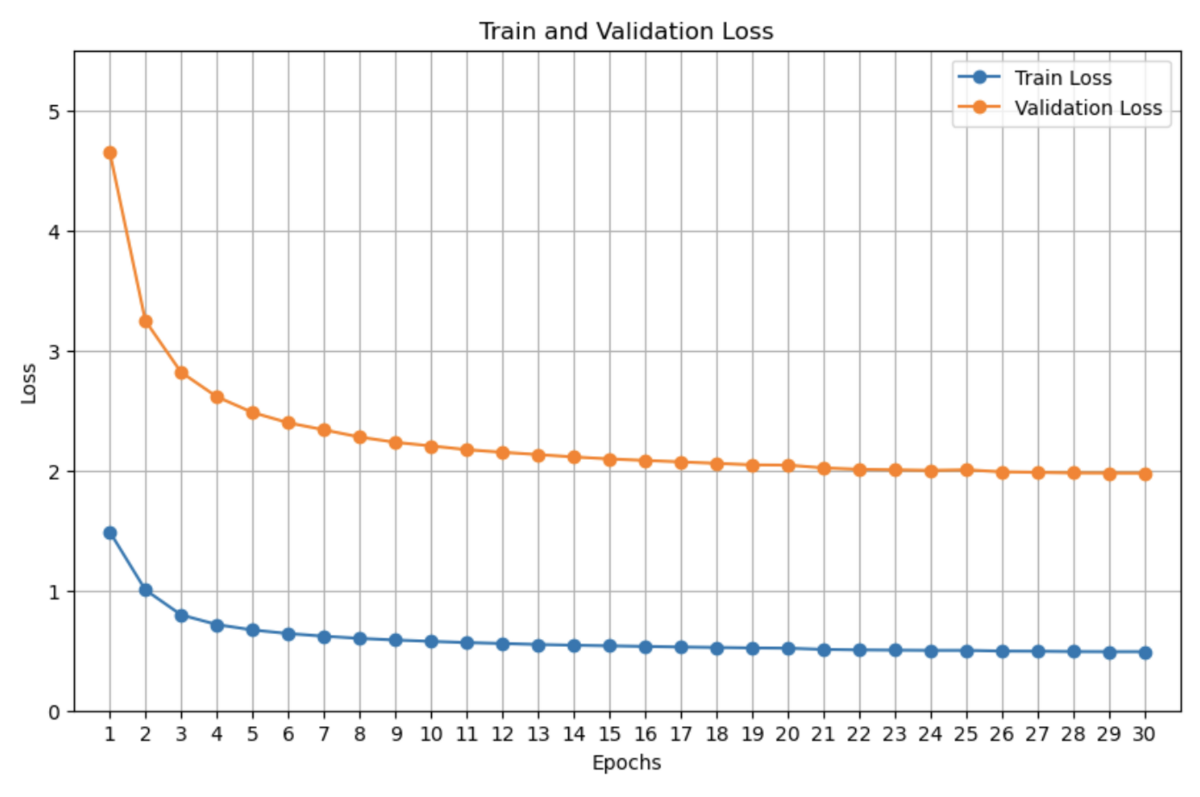
数百万件程度の学習しかしてないので、超大規模にしたときにどうなのかはわからないのですが、「きれいなコーパスをバランスよく使うこと」がめちゃ重要だなと痛感してます。上の翻訳の例を見ても、Transformerはさすがという感じで、両言語間の関係の把握や出力文の文法的な正しさとかの面ではいい仕事をしてるのですが、出力文の単語のチョイスにセンスの無さを感じるので、このへんはコーパス依存の部分が大きいんじゃないかなと。
*1:AWS側のリソースが逼迫しているらしく、運よく空いてる時間に当たらないと起動できない。
*2:TEDの字幕で、品質はとてもいいと思う。
*3:小説のデータで、訳の品質はいいと思うが、英日どちらも文学作品として成り立つように書かれた文章なので、言語的意味が逐一対応しているわけではない気もする。他のコーパスにない特徴として、内容的に連続した文が並んでいるので、連結することで長文のサンプルを作ることができる。
*4:京都に関係するWikipediaのコンテンツを訳したものらしい。訳の品質はいいと思うが、話題が偏っているのと、Wikipediaなので翻訳の学習に適さない情報も混じっている。
*5:色々な映画の字幕の対訳データで、品質はよくデータ量も多くていいのだが、映画の字幕なので1文1文は短め。日常会話のサンプルを稼ぐことができて良いと思う。意訳が多い点がどう出るか。
*6:品質は良いが1文1文は短い。
*7:日本の法令の対訳データ。翻訳自体の品質はよく、また比較的長めのセンテンスが多いところが良いが、内容は当然偏っている。
*8:NTTの研究所がWebクローラを使って自動収集したコーパス。データ量は多いが、変なデータもかなり混じっている印象。
*9:FacebookがWikipediaから作っている多言語の対訳コーパスのうち、英-日分を抜き出したもの。対訳の品質はけっこう良い。
*10:教育分野の話し言葉の対訳コーパスで、品質的にはとても綺麗。1文1文が短いのと、データ量が少ないのが惜しい。
*11:オープンソースのソフトウェアの説明書の対訳データ
*12:学術論文のアブストラクトのデータ。オンライン申請が必要だがすぐにもらえます。
*13:RNNでもそうなのだが、ディープラーニングによる機械翻訳はそれまでの出力結果を受けて次の1語を予測するという流れになっていて、学習が不十分だと、新しい出力を足しても文全体の意味があまり変わらないような場合に同じような表現が繰り返し吐き出される。初期のDeepLで訳文になぜか全く同じ文が連続して入っていたりしたのも同じ理由。