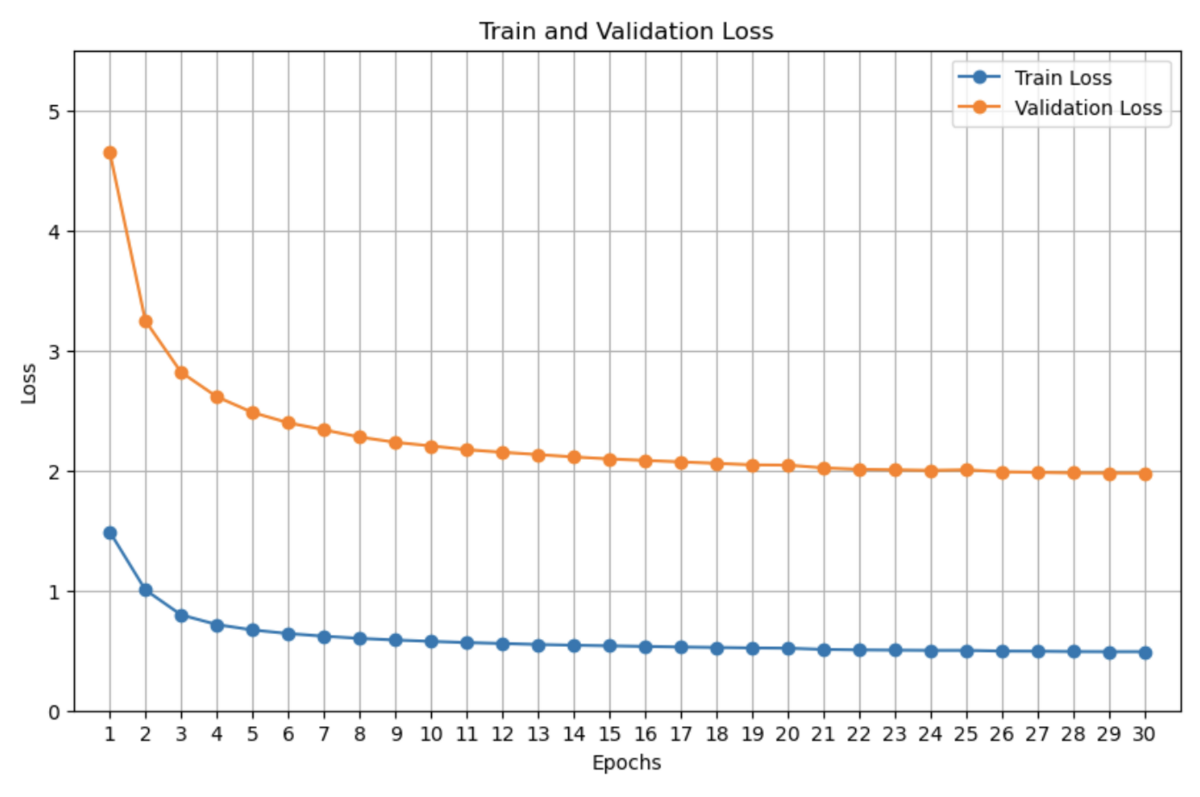
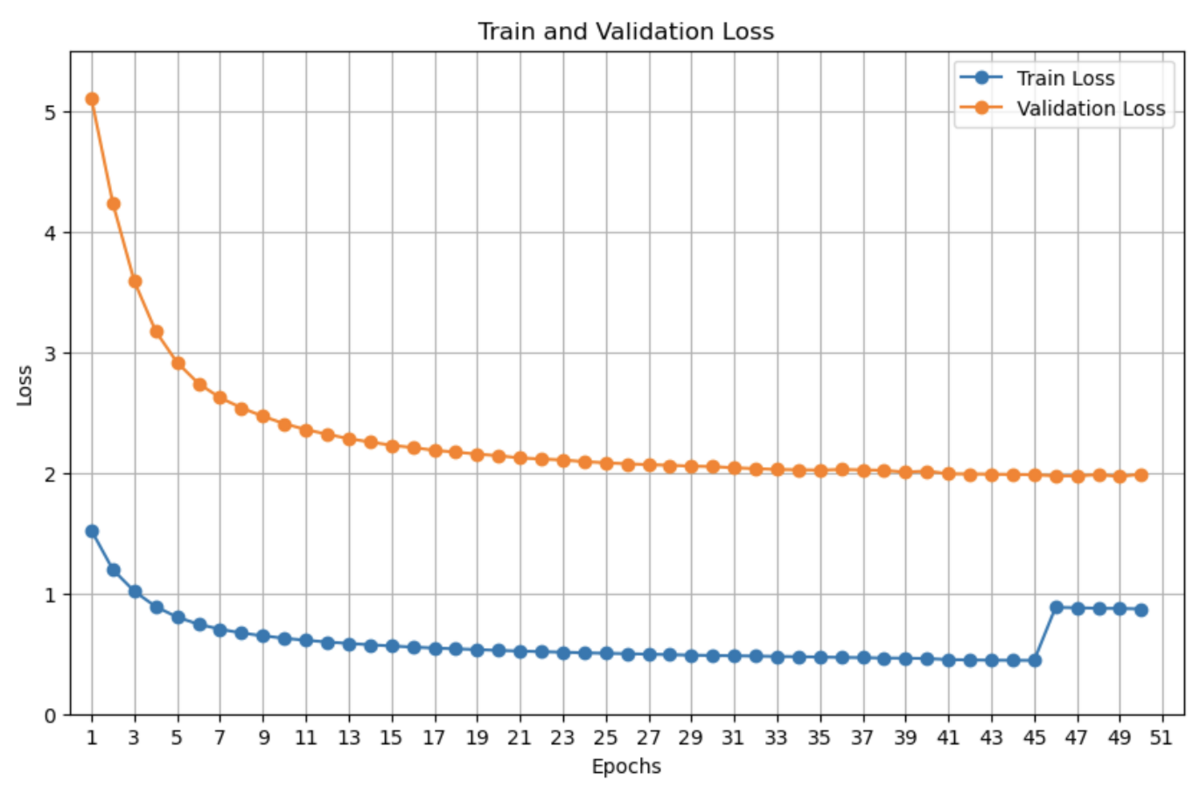
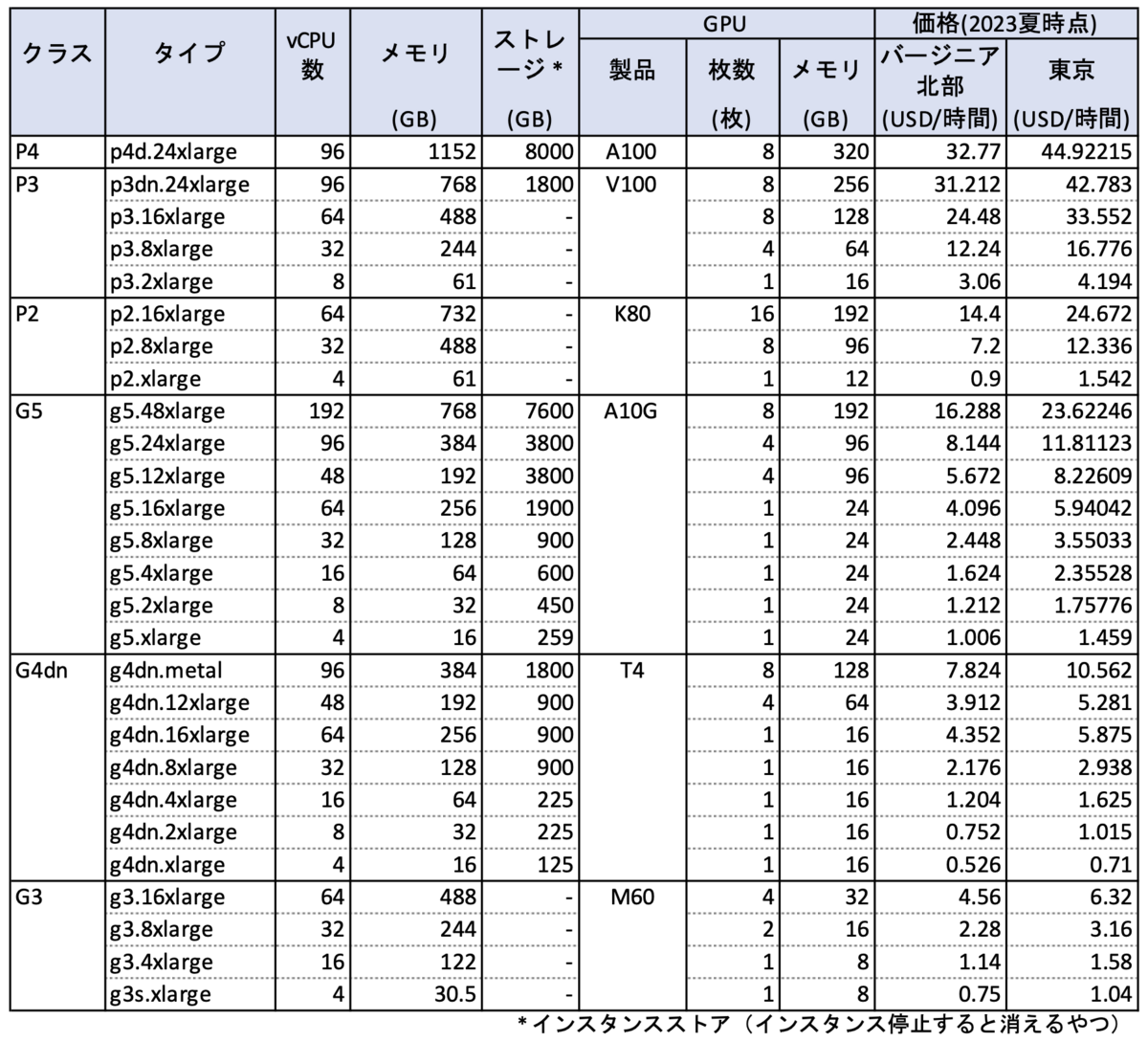
LightGBMにおけるカテゴリ変数の扱いについてググっていたら、以下のような投稿があった。
[SOLVED] How exactly does LightGBM handle the categorical features? | Kaggle
この投稿のなかで、いろいろ参考になるリファレンスが貼られている。
max_cat_to_onehot (default = 4, type = int, constraints: max_cat_to_onehot > 0)
when number of categories of one feature smaller than or equal to max_cat_to_onehot, one-vs-other split algorithm will be used
Parameters — LightGBM 4.2.0.99 documentation
LightGBM offers good accuracy with integer-encoded categorical features. LightGBM applies Fisher (1958) to find the optimal split over categories as described here. This often performs better than one-hot encoding.
Advanced Topics — LightGBM 4.2.0.99 documentation
Optimal Split for Categorical Features
It is common to represent categorical features with one-hot encoding, but this approach is suboptimal for tree learners. Particularly for high-cardinality categorical features, a tree built on one-hot features tends to be unbalanced and needs to grow very deep to achieve good accuracy.Instead of one-hot encoding, the optimal solution is to split on a categorical feature by partitioning its categories into 2 subsets. If the feature has k categories, there are 2^(k-1) - 1 possible partitions. But there is an efficient solution for regression trees[8]. It needs about O(k * log(k)) to find the optimal partition.
The basic idea is to sort the categories according to the training objective at each split. More specifically, LightGBM sorts the histogram (for a categorical feature) according to its accumulated values (sum_gradient / sum_hessian) and then finds the best split on the sorted histogram.
Features — LightGBM 4.2.0.99 documentation
ちなみにFisher(1958)は、斜め読みしかしてないので雰囲気しか把握してないが、1次元の連続値データに基づいてサンプルをグループ分けする際に各グループ内で分散が小さくなるようにするにはどうすればいいかを議論していて、例として200個の数字を10のグループに分ける場合の話がされていた。
ところで、上記投稿者の人自身は、結論を間違えているような気がするな。
この人は、「カテゴリ数(水準数)が`max_cat_to_onehot`以下の場合は、one-vs-other split algorithmが採用され、それより多い場合は、one-hotエンコーディングが採用される」と理解したようなのだが、そもそも水準数が少なければone-hotでいいはずなので、水準数が閾値以下であればone-hot encodingされると理解すべきだろう。
上記3つめの引用に書いてあるように、もともとの問題意識は、カテゴリ数が多い(high-cardinalityな)場合にone-hotエンコーディングをしようとすると非常にアンバランスな木ができてしまい、最適な分割結果に近づくために木を深くしなければならなくなるので、大雑把な分割の中からいいものを選びたいという話である。で、one-vs-other algorythmと呼ばれているものは、one-vs-restと言うことの方が多いようだが、これはようするにone-hotとほぼ同じ意味だと思う。つまり、多クラスの分類を、「あるクラスとそれ以外」に分ける分類器を複数組み合わせて扱うということ。
↓この投稿で検証されているように、`max_cat_to_onehot`よりも少ない水準数の場合は、one-hot encodingした場合と結果が同じになるようだ。
https://stackoverflow.com/questions/65773372/lightgbm-splits-differently-on-the-same-dataset-one-hot-encoded-vs-one-vs-other
(この投稿は、「同じになると思ったらならないんだけど…」という内容で始まって、「あ、バージョン上げたら同じになったわ」と自己解決しているもの。)
で、じゃあカテゴリ数が多い場合にどうなってるのかなのだが、まずそもそも、以下のような「ヒストグラムベース」の木構築の話を頭に入れておかないといけない。
勾配ブースティング決定木ってなんぞや #Python - Qiita
xgboostのコードリーディング(その2) - threecourse’s blog
Kaggleで大人気!勾配ブースティング決定木の軽量モデル「LightGBM」を詳細解説! | DeepSquare
勾配ブースティング決定木においては、ある時点で構築された木に基づく予測値と実際の値から誤差を計算して、誤差関数を「予測値で」偏微分する。つまり、予測値をどっちに動かすと、誤差がどれだけ増えるかを計算する。
ニューラルネットのように、「モデルのパラメータで」偏微分するわけではないので注意が必要。
各ノード(決定木の分岐点)において、特徴空間のどの部分を分割すると、サンプルの勾配の合計が最大限に減少するかを学習していく流れになる。
で、この際、分割点の探索は計算コストが高いので、連続変数ならビンでまとめてヒストグラムのようにした上で、どのビン間で分割するのがよいかを探索することになる。カテゴリ変数(ラベル)の場合は、数量化の工夫を行う必要があって、`(sum_gradient / sum_hessian)`を使ってどうたらこうたらというのは、その話だ。
で、決定木系のアルゴリズムをほとんど勉強してないので単なる想像なのだが、LightGBMにおいて水準数の多いカテゴリ変数扱いは、たぶん以下のような感じなのかな?
全く自信はないのであとで時間あるときに確認しようと思ってるのだけど、誤解だとしても「現時点でどう理解したか」メモっておくのが効率的なので、メモっとくことにするw
- 現時点の木の構築:初期の木、またはブースティングの反復を経た現在の木が与えられる。
- 全サンプルの勾配とヘシアンの計算:各サンプルについて、勾配(損失関数を予測値で一次偏微分)とヘシアン(損失関数を予測値で二次偏微分)を計算する。
- カテゴリ変数を数値に変換:各カテゴリについて、そこに属する属するサンプルの勾配/ヘシアン比の合計値を計算する。この値は、そのカテゴリの重要性を示す。
- カテゴリのソート:カテゴリ変数を、上記の重要度に基づいてソートする。
- ヒストグラム化:ビンでまとめてヒストグラム化する。
- 最適な分割点の探索:Fisher (1958)の手法や他の統計的手法を用いて、どのビン間で分割するのが最も効果的かを探索する。(どう分割すれば勾配をさらに小さくできるかを探索する。)
カテゴリ数が閾値(デフォルトでは4)以下であれば、ふつうにone-hotエンコーディングが採用される。それより大きい場合は、上記のような(誤解ならこれを修正した)手順にしたがって、分割される。なおたぶん、`max_cat_threshold`というパラメータ(デフォルトは32)に設定した値より細かくは分割されないということだと思う。決定木は通常、バイナリ分割(2つに分けていく)で、それを何回か重ねて分けていくが、32分類以上にはしないということだろう。