学習に使ったコード
以下にコードを掲載しておきます。
モジュールをどこで使うのかがわかりやすいように、一番上にまとめてではなくセクションごとにインポートしてます。
セクション名の後に(☆)がついているのは、学習済みモデルを読み込んで推論を行う際に改めて実行する部分です。途中まで学習したモデルを読み込んで追加学習するときも、だいたい同じですが、当然学習に係る部分に要否は異なります。
いろいろ直しながら書いていったコードそのまんまなので、あまり整理されておらず、もっとラップしたりして見やすくしたほうがいいとは思います。
ランタイム立ち上げ、モジュールインポート(☆)
! pip install sentencepiece
from google.colab import drive
drive.mount('/content/drive')
import os
import sys
os.chdir('作業ディレクトリのパスを入れる')
! mkdir /content/save_temp
ディレクトリの決定、パスの設定(☆)
これは完全に私の個人的な都合で設定しているものなので、どうでもいいっちゃどうでもいい。
コーパスとかモデルごとに「プロジェクト」としてまとめようと思ったので、そういうディレクトリ構成になっています。
学習済みもしくは途中まで学習したモデルを読み込んで、追加学習を行ったり推論を行ったりすることがあるわけですが、そのためには関連ファイルをきちんとロードする必要があって、最初は適当にやってたので何度かミスりました。それを避けるために、やや細かくディレクトリを整理しました。
import os
pj_name = 'EJTrans_1.3M'
pj_dir_path = 'projects/' + pj_name
corpus_dir_path = pj_dir_path + '/corpus'
SP_dir_path = pj_dir_path + '/SP'
vocab_dir_path = pj_dir_path + '/vocab'
arch_dir_path = pj_dir_path + '/arch'
model_dir_path = pj_dir_path + '/model'
def check_and_make_dir(path):
if not os.path.exists(path):
os.makedirs(path)
check_and_make_dir(pj_dir_path)
check_and_make_dir(corpus_dir_path)
check_and_make_dir(SP_dir_path)
check_and_make_dir(vocab_dir_path)
check_and_make_dir(arch_dir_path)
check_and_make_dir(model_dir_path)
import datetime
log_filename = f"{pj_dir_path}/training_log.txt"
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
with open(log_filename, "w") as f:
first_line = f"Training Log: created at {current_time}"
f.write(first_line + "\n")
コーパスの事前処理
これもどういうコーパスを使うかによってかわりますが、私は先日のエントリで作成したような、「日本語と英語で1ファイルずつになっていて、行ごとに対訳として対応している」というコーパスファイルを作ってあったので、それを使う前提になっています。
ここでの処理としては、
- 訓練データ、検証データ、テストデータに分割する(結果的に、テストは「適当に英文を入れてみて目視で性能をみる」ことしかやってないので、テストデータは使ってないですがw)
- SentencePieceでバイトペアエンコーディングの学習をする際、All You Need論文にあわせて各言語共通の語彙空間をつくるようにしたので、英語と日本語を(SentencePieceの学習のためだけに)連結したものも作りました。
import shutil
'''リストの1要素を1行ずつテキストファイルに書き込む関数'''
def save_lines(text_list, path):
with open(path, "w") as file:
for l in text_list:
_ = file.write(l)
'''オリジナルコーパスの取得元'''
orig_corpus_en_path = 'data/en_ja_translation/mixed_1.3M_en.txt'
orig_corpus_ja_path = 'data/en_ja_translation/mixed_1.3M_ja.txt'
'''作成するコーパスのパスを予め指定'''
corpus_en_path = corpus_dir_path + '/corpus_en.txt'
corpus_ja_path = corpus_dir_path + '/corpus_ja.txt'
'''コーパスを元データ置き場から本プロジェクトのディレクトリにコピー配置'''
shutil.copyfile(orig_corpus_en_path, corpus_en_path)
shutil.copyfile(orig_corpus_ja_path, corpus_ja_path)
'''上記コーパスの読み込み'''
with open(corpus_en_path) as f:
corpus_en = f.readlines()
with open(corpus_ja_path) as f:
corpus_ja = f.readlines()
'''コーパスのサイズを限定する処理(デフォルトは全部利用)'''
full_corpus_len = len(corpus_en)
corpus_size = full_corpus_len
if corpus_size < full_corpus_len:
corpus_en = corpus_en[:corpus_size]
corpus_ja = corpus_ja[:corpus_size]
if corpus_size < full_corpus_len:
save_lines(corpus_en, corpus_en_path)
save_lines(corpus_ja, corpus_ja_path)
'''コーパスを訓練用・検証用・テスト用に分割'''
split_ratio = [0.9, 0.05, 0.05]
def split_corpus(corpus, split_ratio, role, save_path):
end_train = round(len(corpus)*split_ratio[0])
end_valid = end_train + round(len(corpus)*split_ratio[1])
if role=='train':
save_lines(corpus[:end_train], save_path)
if role=='valid':
save_lines(corpus[end_train:end_valid], save_path)
if role=='test':
save_lines(corpus[end_valid:], save_path)
split_corpus(corpus_en, split_ratio, 'train', corpus_dir_path + '/corpus_en_train.txt')
split_corpus(corpus_en, split_ratio, 'valid', corpus_dir_path + '/corpus_en_valid.txt')
split_corpus(corpus_en, split_ratio, 'test', corpus_dir_path + '/corpus_en_test.txt')
split_corpus(corpus_ja, split_ratio, 'train', corpus_dir_path + '/corpus_ja_train.txt')
split_corpus(corpus_ja, split_ratio, 'valid', corpus_dir_path + '/corpus_ja_valid.txt')
split_corpus(corpus_ja, split_ratio, 'test', corpus_dir_path + '/corpus_ja_test.txt')
'''訓練コーパスの英語・日本語を連結したものを作成(SentencePiece用)'''
with open(corpus_dir_path + '/corpus_en_train.txt') as f:
corpus_en_train = f.readlines()
with open(corpus_dir_path + '/corpus_ja_train.txt') as f:
corpus_ja_train = f.readlines()
save_lines(corpus_en_train + corpus_ja_train, corpus_dir_path + '/corpus_enja_train.txt')
トークナイザの構築
トークナイザのセクションで必要な作業は、
- BPEによって文章をサブワード(文字と単語の間ぐらいの中途半端な単位)に分割する
- サブワードにIDをふって語彙空間を生成する
- 開始記号、終了記号、未知語記号、パディング記号を定義して語彙空間にセットする
です。
なお、SentencePieceの学習にはけっこう時間がかかる(今回のデータ量で数十分)ので、1回構築したら、Transformerの学習中/済みモデルを読み込んで追加学習や推論を行う際は、SentencePieceのモデルも単に読み込むだけにしたほうがいいです。
チュートリアルの変数名は意味不明だったので変更しています。それ以外にもいろいろいじった気がする。
import sentencepiece as spm
corppus_enja_path = corpus_dir_path + '/corpus_enja_train.txt'
sp_model_path = SP_dir_path + '/sp'
vocab_size = '30000'
sp_command = '--input=' + corppus_enja_path + ' --model_prefix=' + sp_model_path + ' --vocab_size=' + vocab_size + ' --character_coverage=0.995 --model_type=bpe'
spm.SentencePieceTrainer.train(sp_command)
import sentencepiece as spm
import torch
from torchtext.vocab import build_vocab_from_iterator
'''SentencePieceの学習済みデータのロード'''
sp = spm.SentencePieceProcessor()
sp.load(SP_dir_path + '/sp.model')
'''src側とtgt側の言語の設定'''
SRC_LANGUAGE = 'en'
TGT_LANGUAGE = 'ja'
'''文字列をサブワードに分割する“text_to_subwords”の構築'''
def sp_splitter(sp_model):
def get_subwords(text):
return sp_model.encode_as_pieces(text)
return get_subwords
text_to_subwords = {}
text_to_subwords[SRC_LANGUAGE] = sp_splitter(sp)
text_to_subwords[TGT_LANGUAGE] = sp_splitter(sp)
'''サブワードをID化する“subwords_to_ids”の構築'''
def file_to_subwords(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
yield sp.encode_as_pieces(line)
UNK_IDX, PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2, 3
special_symbols = ['<unk>', '<pad>', '<bos>', '<eos>']
subwords_to_ids = {}
subwords_to_ids[SRC_LANGUAGE] = build_vocab_from_iterator(file_to_subwords(corpus_dir_path + '/corpus_en_train.txt'), min_freq=1, specials=special_symbols, special_first=True)
subwords_to_ids[TGT_LANGUAGE] = build_vocab_from_iterator(file_to_subwords(corpus_dir_path + '/corpus_ja_train.txt'), min_freq=1, specials=special_symbols, special_first=True)
for ln in [SRC_LANGUAGE, TGT_LANGUAGE]:
subwords_to_ids[ln].set_default_index(UNK_IDX)
'''ボキャブラリの保存'''
torch.save(subwords_to_ids[SRC_LANGUAGE], vocab_dir_path + '/vocab_en.pth')
torch.save(subwords_to_ids[TGT_LANGUAGE], vocab_dir_path + '/vocab_ja.pth')
トークナイザのロード(☆)
これは、学習中/済みモデルをロードして、学習を再開したり推論を行ったりする場合に使用する部分です。最初の学習時は実行しません(しても問題ないけど)。
import sentencepiece as spm
import torch
SRC_LANGUAGE = 'en'
TGT_LANGUAGE = 'ja'
'''サブワード分割器のロード'''
sp = spm.SentencePieceProcessor()
sp.load(SP_dir_path + '/sp.model')
def sp_splitter(sp_model):
def get_subwords(text):
return sp_model.encode_as_pieces(text)
return get_subwords
text_to_subwords = {}
text_to_subwords[SRC_LANGUAGE] = sp_splitter(sp)
text_to_subwords[TGT_LANGUAGE] = sp_splitter(sp)
'''ID変換器(ボキャブラリ)のロード'''
subwords_to_ids = {}
subwords_to_ids[SRC_LANGUAGE] = torch.load(vocab_dir_path + '/vocab_en.pth')
subwords_to_ids[TGT_LANGUAGE] = torch.load(vocab_dir_path + '/vocab_ja.pth')
テキスト→テンソル変換器(☆)
テキストを、モデルに入れられる形のテンソルに変換するための部品です。チュートリアルではもっと下のほうに書いてあったのですが、分かりにくいので上にもってきています。
from torch.nn.utils.rnn import pad_sequence
from typing import List
BOS_IDX = subwords_to_ids[SRC_LANGUAGE]['<bos>']
EOS_IDX = subwords_to_ids[SRC_LANGUAGE]['<eos>']
def add_bos_eos(token_ids: List[int]):
return torch.cat((torch.tensor([BOS_IDX]),
torch.tensor(token_ids),
torch.tensor([EOS_IDX])))
def sequential_transforms_src(input):
tok_out = text_to_subwords[SRC_LANGUAGE](input)
voc_out = subwords_to_ids[SRC_LANGUAGE](tok_out)
ten_out = add_bos_eos(voc_out)
return ten_out
def sequential_transforms_tgt(input):
tok_out = text_to_subwords[TGT_LANGUAGE](input)
voc_out = subwords_to_ids[TGT_LANGUAGE](tok_out)
ten_out = add_bos_eos(voc_out)
return ten_out
text_to_tensor = {}
text_to_tensor[SRC_LANGUAGE] = sequential_transforms_src
text_to_tensor[TGT_LANGUAGE] = sequential_transforms_tgt
text_to_tensor['en']('apple')
ここがモデルのコア部分です。
from torch import Tensor
import torch
import torch.nn as nn
from torch.nn import Transformer
import math
'''ポジショナルエンコーディング(チュートリアル通り)'''
class PositionalEncoding(nn.Module):
def __init__(self,
emb_size: int,
dropout: float,
maxlen: int = 5000):
super(PositionalEncoding, self).__init__()
den = torch.exp(- torch.arange(0, emb_size, 2)* math.log(10000) / emb_size)
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
pos_embedding = torch.zeros((maxlen, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.Dropout(dropout)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :])
'''埋め込み(チュートリアル通り)'''
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
'''Transformer本体(チュートリアル通り)'''
class Seq2SeqTransformer(nn.Module):
def __init__(self,
num_encoder_layers: int,
num_decoder_layers: int,
emb_size: int,
nhead: int,
src_vocab_size: int,
tgt_vocab_size: int,
dim_feedforward: int = 512,
dropout: float = 0.1):
super(Seq2SeqTransformer, self).__init__()
self.transformer = Transformer(d_model=emb_size,
nhead=nhead,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
dim_feedforward=dim_feedforward,
dropout=dropout)
self.generator = nn.Linear(emb_size, tgt_vocab_size)
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(
emb_size, dropout=dropout)
def forward(self,
src: Tensor,
trg: Tensor,
src_mask: Tensor,
tgt_mask: Tensor,
src_padding_mask: Tensor,
tgt_padding_mask: Tensor,
memory_key_padding_mask: Tensor):
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
outs = self.transformer(src_emb, tgt_emb, src_mask, tgt_mask, None,
src_padding_mask, tgt_padding_mask, memory_key_padding_mask)
return self.generator(outs)
def encode(self, src: Tensor, src_mask: Tensor):
return self.transformer.encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
return self.transformer.decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)
'''マスクの生成(チュートリアル通り)'''
PAD_IDX = subwords_to_ids[SRC_LANGUAGE]['<pad>']
'''
正方行列の上三角部分に True、それ以外に False を持つ行列を生成する。
その後、Trueの要素を-infに、Falseの要素を0.0に置き換える。
'''
def generate_square_subsequent_mask(sz):
mask = (torch.triu(torch.ones((sz, sz), device=DEVICE)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
src_mask = torch.zeros((src_seq_len, src_seq_len),device=DEVICE).type(torch.bool)
src_padding_mask = (src == PAD_IDX).transpose(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
ここでアークテクチャと言っているのは、Transformerのモデルの各パーツのサイズみたいな感じです。
あとで呼び出すことがあるので、PyTorchのオブジェクトとして保存してます。
'''モデルアーキテクチャの設定と保存'''
model_arch = {
'NUM_ENCODER_LAYERS':3,
'NUM_DECODER_LAYERS':3,
'EMB_SIZE':512,
'NHEAD':8,
'SRC_VOCAB_SIZE':len(subwords_to_ids[SRC_LANGUAGE]),
'TGT_VOCAB_SIZE':len(subwords_to_ids[TGT_LANGUAGE]),
'FFN_HID_DIM':512
}
torch.save(model_arch, arch_dir_path + '/model_arch.pth')
学習の準備
Transformerモデルのアーキテクチャを設定してインスタンスを作成したり、オプティマイザのインスタンスを作成したりしています。学習率のスケジューリングを書くのが面倒だったので、固定にしてますが、エポックの進展にあわせて小さくしていくようにしたほうがいいとは思います。私は、途中まで学習して止めて、モデルをロードしてまた追加学習するということを繰り返していたので、手動で途中からlrを小さくしましたw
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
'''(A) 最初から学習する場合の準備'''
transformer = Seq2SeqTransformer(num_encoder_layers = model_arch['NUM_ENCODER_LAYERS'],
num_decoder_layers = model_arch['NUM_DECODER_LAYERS'],
emb_size = model_arch['EMB_SIZE'],
nhead = model_arch['NHEAD'],
src_vocab_size = model_arch['SRC_VOCAB_SIZE'],
tgt_vocab_size = model_arch['TGT_VOCAB_SIZE'],
dim_feedforward = model_arch['FFN_HID_DIM'])
torch.manual_seed(0)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
transformer = transformer.to(DEVICE)
PAD_IDX = subwords_to_ids[SRC_LANGUAGE]['<pad>']
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
'''(B) 途中から学習を再開する場合の準備'''
model_arch = torch.load(arch_dir_path + '/model_arch.pth')
transformer = Seq2SeqTransformer(num_encoder_layers = model_arch['NUM_ENCODER_LAYERS'],
num_decoder_layers = model_arch['NUM_DECODER_LAYERS'],
emb_size = model_arch['EMB_SIZE'],
nhead = model_arch['NHEAD'],
src_vocab_size = model_arch['SRC_VOCAB_SIZE'],
tgt_vocab_size = model_arch['TGT_VOCAB_SIZE'],
dim_feedforward = model_arch['FFN_HID_DIM'])
transformer.to(DEVICE)
transformer.load_state_dict(torch.load(model_dir_path + '/best_model_epoch=25_valloss=2.400.pth'))
PAD_IDX = subwords_to_ids[SRC_LANGUAGE]['<pad>']
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.Adam(transformer.parameters(), lr=0.00001, betas=(0.9, 0.98), eps=1e-9)
データローダのセット
学習時に、コーパスの中からデータを取って、バッチにまとめてモデルに供給していく装置です。
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
BATCH_SIZE = 128
class CustomDataset(Dataset):
def __init__(self, src_path, tgt_path):
with open(src_path, 'r', encoding='utf-8') as f:
self.src_data = [line.strip() for line in f]
with open(tgt_path, 'r', encoding='utf-8') as f:
self.tgt_data = [line.strip() for line in f]
def __len__(self):
return len(self.src_data)
def __getitem__(self, idx):
return self.src_data[idx], self.tgt_data[idx]
PAD_IDX = subwords_to_ids[SRC_LANGUAGE]['<pad>']
def collate_fn(batch):
src_batch, tgt_batch = [], []
for src_sample, tgt_sample in batch:
src_batch.append(text_to_tensor[SRC_LANGUAGE](src_sample.rstrip("\n")))
tgt_batch.append(text_to_tensor[TGT_LANGUAGE](tgt_sample.rstrip("\n")))
src_batch = pad_sequence(src_batch, padding_value=PAD_IDX)
tgt_batch = pad_sequence(tgt_batch, padding_value=PAD_IDX)
return src_batch, tgt_batch
train_dataset = CustomDataset(corpus_dir_path + '/corpus_en_train.txt', corpus_dir_path + '/corpus_ja_train.txt')
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn)
val_dataset = CustomDataset(corpus_dir_path + '/corpus_en_valid.txt', corpus_dir_path + '/corpus_ja_valid.txt')
val_dataloader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn)
学習ルーチン
学習と検証のルーチンです。勾配累積を使うようにチュートリアルから変更してます。
from torch.utils.data import DataLoader
GRADIENT_ACCUMULATION_STEPS = 2
'''新しい訓練ルーチン'''
def train_epoch(model, optimizer, train_dataloader):
model.train()
losses = 0
for step, (src, tgt) in enumerate(train_dataloader):
src = src.to(DEVICE)
tgt = tgt.to(DEVICE)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask, src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
loss = loss / GRADIENT_ACCUMULATION_STEPS
loss.backward()
losses += loss.item()
if (step + 1) % GRADIENT_ACCUMULATION_STEPS == 0:
optimizer.step()
optimizer.zero_grad()
return losses / len(list(train_dataloader))
'''検証ルーチン'''
def evaluate(model, val_dataloader):
model.eval()
losses = 0
for src, tgt in val_dataloader:
src = src.to(DEVICE)
tgt = tgt.to(DEVICE)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
losses += loss.item()
return losses / len(list(val_dataloader))
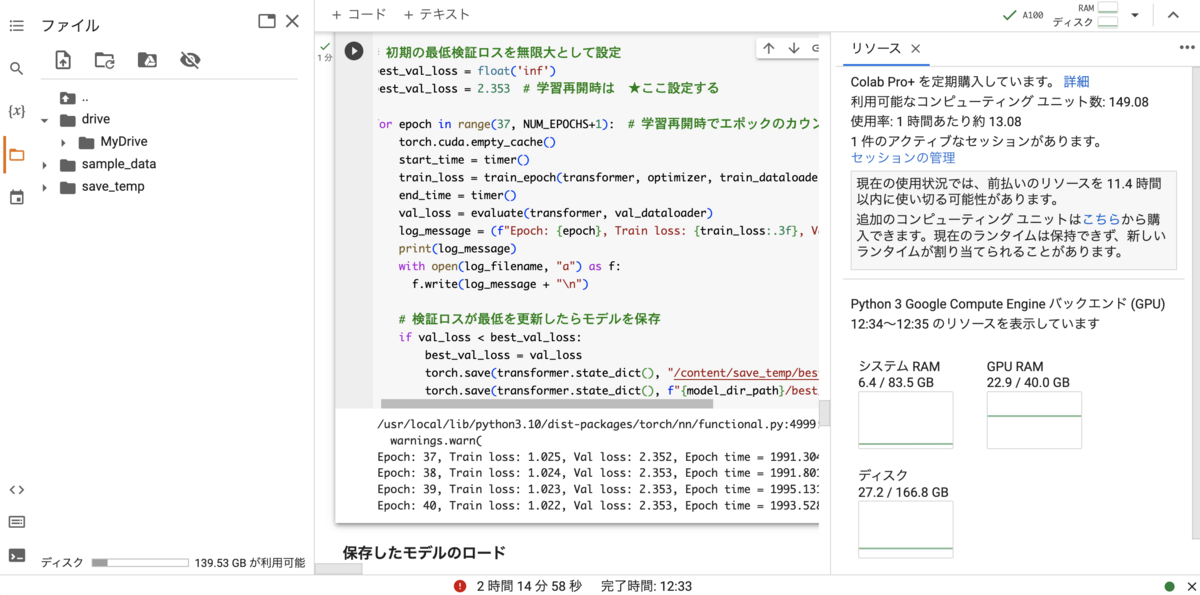
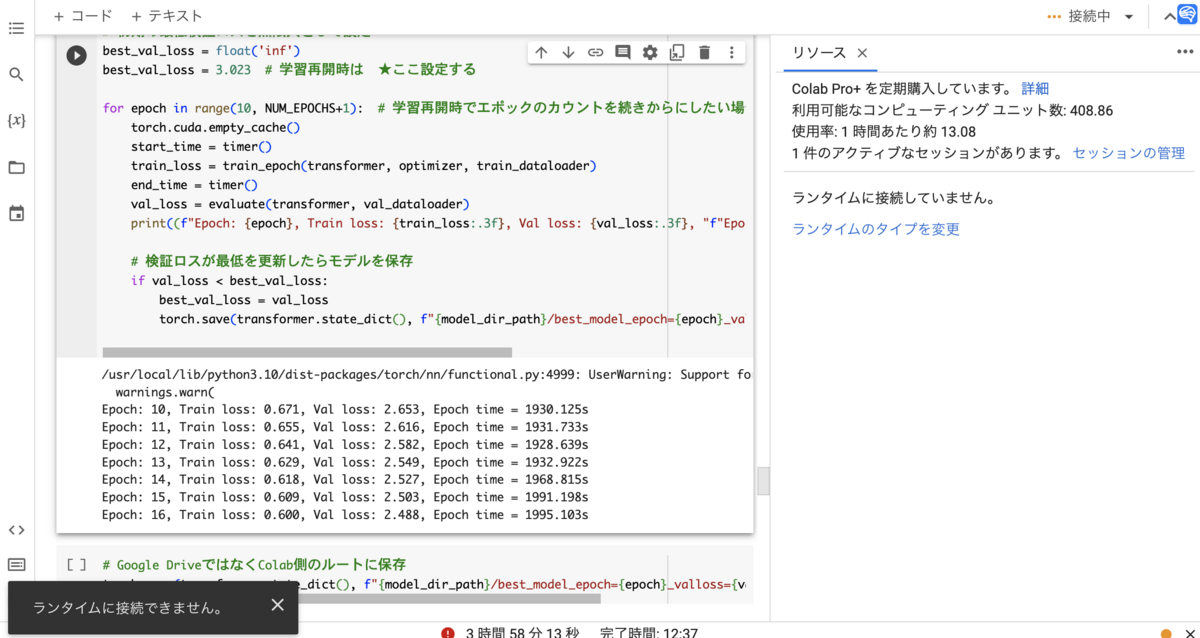
学習の実施
以下で学習を進めるのですが、要するに
train_loss = train_epoch(transformer, optimizer, train_dataloader)
の部分でローダからデータがモデルに供給されて、勾配が計算されたりパラメータが更新されたりしていきます。
検証ロスがベストを更新したら、モデルを保存するようにしています。その際、Google Colabの不具合でGoogle Driveとの接続がおかしくなることがあるので、Colabサーバ側でもモデルを保存するようにしています。これは緊急時にここからモデルを救うというものなので、別に保存してなくてもいいといえばいいです。
あと、ログを書き込むようにしてます。
'''学習の実施'''
from timeit import default_timer as timer
NUM_EPOCHS = 35
best_val_loss = float('inf')
for epoch in range(1, NUM_EPOCHS+1):
torch.cuda.empty_cache()
start_time = timer()
train_loss = train_epoch(transformer, optimizer, train_dataloader)
end_time = timer()
val_loss = evaluate(transformer, val_dataloader)
log_message = (f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Val loss: {val_loss:.3f}, "f"Epoch time = {(end_time - start_time):.3f}s")
print(log_message)
with open(log_filename, "a") as f:
f.write(log_message + "\n")
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(transformer.state_dict(), "/content/save_temp/best_model.pth")
torch.save(transformer.state_dict(), f"{model_dir_path}/best_model_epoch={epoch}_valloss={val_loss:.3f}.pth")
保存したモデルのロード(☆)
ここは、追加学習や推論時に何が必要かをちゃんと理解して、整理しておく必要があります。
'''①以下のセクションをすべて実行する'''
'''②モデルアーキテクチャ(ハイパーパラメータ)のロード'''
model_arch = torch.load(arch_dir_path + '/model_arch.pth')
'''③モデルのインスタンス構築'''
transformer = Seq2SeqTransformer(num_encoder_layers = model_arch['NUM_ENCODER_LAYERS'],
num_decoder_layers = model_arch['NUM_DECODER_LAYERS'],
emb_size = model_arch['EMB_SIZE'],
nhead = model_arch['NHEAD'],
src_vocab_size = model_arch['SRC_VOCAB_SIZE'],
tgt_vocab_size = model_arch['TGT_VOCAB_SIZE'],
dim_feedforward = model_arch['FFN_HID_DIM'])
transformer.to(DEVICE)
'''④保存済みパラメータをロード'''
transformer.load_state_dict(torch.load(model_dir_path + '/best_model.pth'))
パラメータ数とトークン数の確認
別にどうでもいいと言えばどうでもいいですが、モデルのパラメータ数やデータのトークン数をカウントしたいとき用。
num_params = sum(p.numel() for p in transformer.parameters())
print(num_params)
with open(corpus_dir_path + '/corpus_en_train.txt') as f:
corpus_en = f.readlines()
with open(corpus_dir_path + '/corpus_ja_train.txt') as f:
corpus_ja = f.readlines()
num_token_en = 0
for text in corpus_en:
token_ids = subwords_to_ids[SRC_LANGUAGE](text_to_subwords[SRC_LANGUAGE](text))
num_token_en += len(token_ids)
num_token_ja = 0
for text in corpus_ja:
token_ids = subwords_to_ids[TGT_LANGUAGE](text_to_subwords[TGT_LANGUAGE](text))
num_token_ja += len(token_ids)
print("Number of English tokens:", num_token_en)
print("Number of English tokens:", num_token_ja)
print("Number of pairs of parallel corpus:", len(corpus_en))
推論の関数(貪欲法)
推論を実施するための関数です。
'''貪欲法での推論の関数'''
def greedy_decode(model, src, src_mask, max_len, start_symbol):
src = src.to(DEVICE)
src_mask = src_mask.to(DEVICE)
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(DEVICE)
for i in range(max_len-1):
memory = memory.to(DEVICE)
tgt_mask = (generate_square_subsequent_mask(ys.size(0))
.type(torch.bool)).to(DEVICE)
out = model.decode(ys, memory, tgt_mask)
out = out.transpose(0, 1)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.item()
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
if next_word == EOS_IDX:
break
return ys
def translate(model: torch.nn.Module, src_sentence: str):
model.eval()
src = text_to_tensor[SRC_LANGUAGE](src_sentence).view(-1, 1)
num_tokens = src.shape[0]
src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
tgt_tokens = greedy_decode(
model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()
return " ".join(subwords_to_ids[TGT_LANGUAGE].lookup_tokens(list(tgt_tokens.cpu().numpy()))).replace("<bos>", "").replace("<eos>", "").replace(" ", "").replace("▁", "")
'''ビームサーチでの推論の関数'''
import heapq
def beam_search_decode(model, src, src_mask, max_len, start_symbol, beam_size):
src = src.to(DEVICE)
src_mask = src_mask.to(DEVICE)
memory = model.encode(src, src_mask)
initial_input = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(DEVICE)
hypotheses = [(0.0, initial_input)]
completed_hypotheses = []
for _ in range(max_len - 1):
new_hypotheses = []
for score, prev_output in hypotheses:
prev_output = prev_output.to(DEVICE)
tgt_mask = (generate_square_subsequent_mask(prev_output.size(0))
.type(torch.bool)).to(DEVICE)
out = model.decode(prev_output, memory, tgt_mask)
out = out.transpose(0, 1)
prob = model.generator(out[:, -1])
topk_probs, topk_indices = torch.topk(prob, beam_size)
for prob, next_word in zip(topk_probs[0], topk_indices[0]):
new_score = score + prob.item()
new_output = torch.cat([prev_output, next_word.view(1, 1)], dim=0)
new_hypotheses.append((new_score, new_output))
new_hypotheses.sort(reverse=True, key=lambda x: x[0])
hypotheses = new_hypotheses[:beam_size]
completed_hypotheses = [hypothesis for hypothesis in hypotheses if hypothesis[1][-1].item() == EOS_IDX]
if len(completed_hypotheses) >= beam_size:
break
best_hypothesis = max(hypotheses, key=lambda x: x[0])[1]
return best_hypothesis.flatten()
def translate_beam_search(model: torch.nn.Module, src_sentence: str, beam_size: int):
model.eval()
src = text_to_tensor[SRC_LANGUAGE](src_sentence).view(-1, 1)
num_tokens = src.shape[0]
src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
tgt_tokens = beam_search_decode(
model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX, beam_size=beam_size).flatten()
return " ".join(subwords_to_ids[TGT_LANGUAGE].lookup_tokens(list(tgt_tokens.cpu().numpy()))).replace("<bos>", "").replace("<eos>", "").replace(" ", "").replace("▁", "")
推論(翻訳)の実施
いよいよ翻訳をやってみます。
eng = ['I am a pen.',
'Your time is limited, so don’t waste it living someone else’s life.',
'I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character.',
'You are fake news!',
'You may say I\'m a dreamer. But I\'m not the only one. I hope someday you\'ll join us. And the world will be as one.',
'The madman is not the man who has lost his reason. The madman is the man who has lost everything except his reason.',
'We are being afflicted with a new disease of which some readers may not yet have heard the name, but of which they will hear a great deal in the years to come—namely, technological unemployment. This means unemployment due to our discovery of means of economising the use of labour outrunning the pace at which we can find new uses for labour. But this is only a temporary phase of maladjustment. All this means in the long run that mankind is solving its economic problem. I would predict that the standard of life in progressive countries one hundred years hence will be between four and eight times as high as it is. There would be nothing surprising in this even in the light of our present knowledge. It would not be foolish to contemplate the possibility of afar greater progress still.'
]
for e in eng:
print(e + '\n' + translate(transformer, e) + '\n')
for e in eng:
print(e + '\n' + translate_beam_search(transformer, e, 5) + '\n')